Cloudize Framework Performance Report

Abstract
Cloudize is a software development consultancy specialising in providing its customers with the capability to innovate at extraordinary speed through its API technologies.
Creating beautiful APIs is a highly specialised undertaking, and this is where we bring a significant point of difference to the table. Not only do we bring this specialist know-how and our build-as-you-design tooling to the table, but perhaps more significantly, we bring the ability to deliver iterations at extreme speed - often in real-time during the design process.
We are committed to creating world-class cloud platforms which enable our customers to capture new markets, disrupt industries, and leapfrog their competitors.
Test Objectives
This test suite demonstrates the delivery of an API capable of serving a sustained throughput of no less than 1 million requests per minute with the following performance objectives:
- P50 transaction time targeting 5 milliseconds,
- P75 transaction time targeting 10 milliseconds,
- P85 transaction time targeting 50 milliseconds,
- P90 transaction time targeting 500 milliseconds,
- P95 transaction time targeting 1000 milliseconds,
- P98 transaction time targeting 2000 milliseconds,
Generally speaking, most problems of this nature can be solved by throwing enough hardware (money) at the problem. However, maintaining operational cost efficiency is a significant focal point for most businesses, and therefore, to keep the solution firmly anchored in the real world, a cost limitation of $10K per month has been imposed on the database implementation for this test. In addition, a target of no more than $1 per million transactions has been set for the variable operational costs of the service.
The API in this test will serve resources from a database containing no less than 100 million records. Authentication and role-based authorisation will secure the API, and performance metrics of each transaction will be recorded within a telemetry database.
Implementation
In the simplest terms, the solution consists of two software components, which we have named Shield and Hydra.
Shield is the API service, along with its corresponding database, and Hydra is the testing client component
The Shield API is a default implementation of the Cloudize API Framework as produced by our API design tooling with no specific customisation. For the purpose of this test, it is deployed within AWS using our default infrastructure as code templates.
The Address resources served by the API have the following shape.
{
"type": "Address",
"id": "e818cedd-6dd6-42ab-b632-d5f3ab663a31",
"attributes": {
"seq": 82917383,
"address": {
"country": { "name": "Australia", "code": "AU" },
"number": {
"range": { "firstNumber": 5, "lastNumber": 5 },
"text": "5"
},
"street": "Hilltop Close",
"suburb": "Narre Warren South"
},
"fullAddress": "5 Hilltop Close, Narre Warren South, VIC, 3805, Australia",
"location": { "longitude": 145.310859849681, "latitude": -38.0533598629114 }
},
"links": {
"self": "https://api.domain.name/v1/system/addresses/e818cedd-6dd6-42ab-b632-d5f3ab663a31"
},
"meta": { "insertedAt": "2022-09-08T17:29:10.023Z" }
}The Hydra application is essentially an event wrapper around the Shield SDK, which was also produced by our API design tooling.
Address resources within the system have a unique auto-incrementing "seq" attribute, and the API allows filtering by that attribute as per the following excerpt from the API documentation that was generated by our API design tooling.
The filter[seq] query string parameter enables the consumer to filter resources with an equality match on the value provided. The value must comply with the data schema specification before it is considered for processing.
Each instance of the Hydra application simulates 50 concurrent users which repeatedly query the API for a random Address resource by using the filter[seq] filter with a random value between 1 and 100,000,000.
Finally, the Hydra application implements a 10-minute ramp-up period, after which it runs at full speed for the remainder of the test. Each of the 50 simulated users within the Hydra application performs 10,000 queries before the application terminates.
Architecture
The following architecture diagram visualises the infrastructure implemented in the solution.
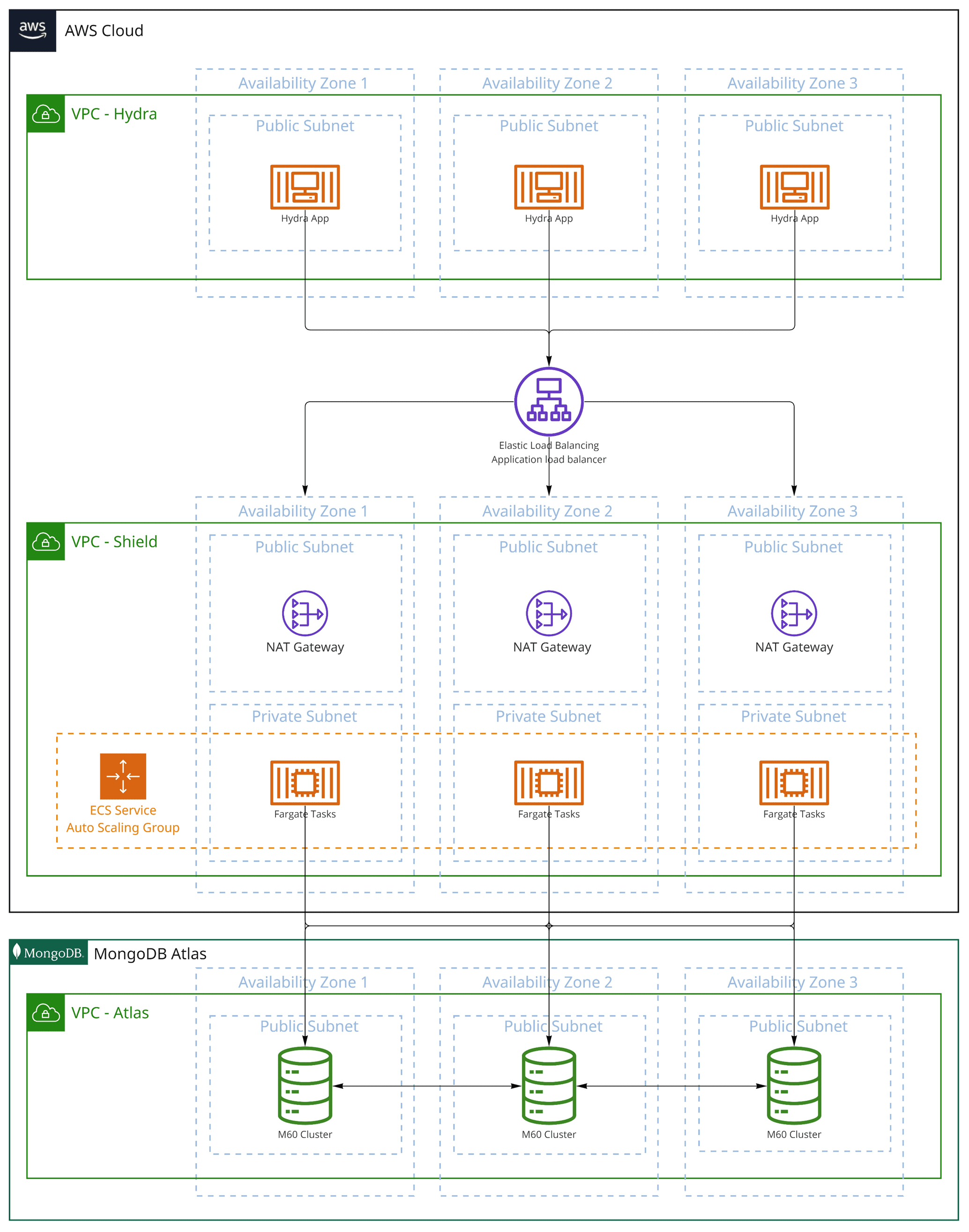
Database configuration
We implemented a MongoDB Atlas M60 database cluster within AWS for this test. Given the read-heavy requirements of this test, the database cluster configuration had three standard (electable) nodes and six read-only nodes.
The database was optimised and indexed using the standard database indexing scripts created by our API design tooling.
The Shield API
During the API design phase of the solution, it was identified that whilst Address resources are read frequently, they are updated very infrequently. As a result, the solution was automatically optimised by our design tooling to take advantage of the significant read capacity within the database cluster whilst reducing the load on the primary server.
The compute platform which we deployed for this test utilised AWS Fargate Tasks managed by ECS across three availability zones. Autoscaling used target tracking on CPU, Memory and Request Count per Target dimensions. Each Task was allocated 1 full vCpu and 2GB RAM.
The design and development of the API took 2 hours, and configuring the AWS infrastructure to run the API took an additional hour.
The Hydra Test Application
Once again, the compute platform selected for the Hydra application was AWS Fargate, deployed across three availability zones in AWS. Each Hydra Task was allocated 1 full vCpu and 2GB RAM. For the purpose of this test, we deployed 60 Hydra tasks, equating to 3000 simulated users constantly accessing random resources from the API.
The Results
As you can see from the graph below, we quite easily achieved our stated goal of delivering an API capable of serving 1 million requests per minute. We could easily have significantly exceeded this goal had we not put a sensible cost cap on the test solution.
The average end-to-end transaction time was 137.5ms, while the median transaction time came at an incredible 3.7ms. These are both excellent results for an API backed by a database of this size under this level of load.
As seen below, the solution was stable and produced excellent consistency in both throughput and transactional performance.
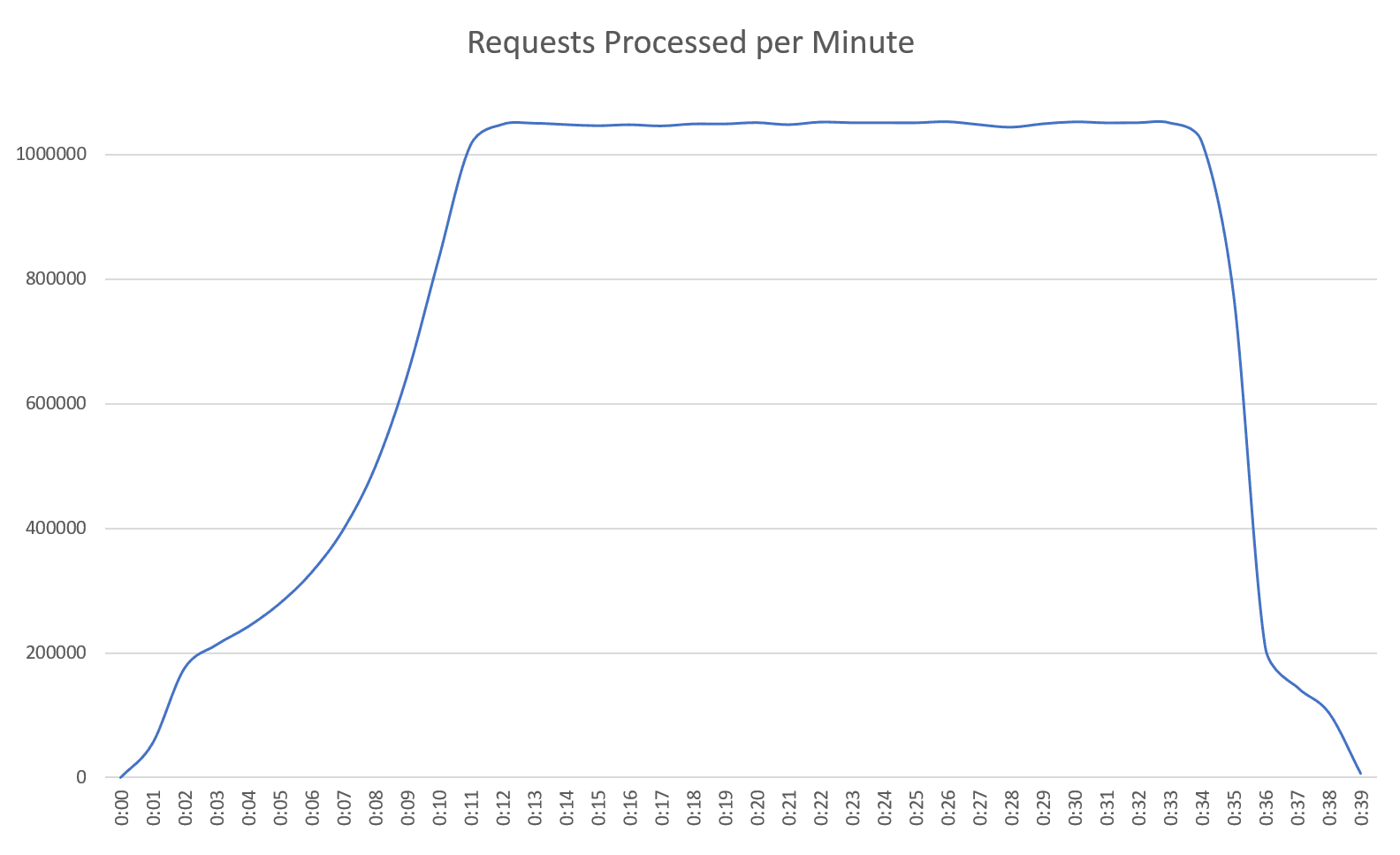
You may recall that when defining the test, we specified the following performance goals:
- P50 targetting 5 milliseconds,
- P75 targetting 10 milliseconds,
- P85 targetting 50 milliseconds,
- P90 targetting 500 milliseconds,
- P95 targetting 1000 milliseconds,
- P98 targetting 2000 milliseconds,
The following graph shows the response time performance of the API by percentile.
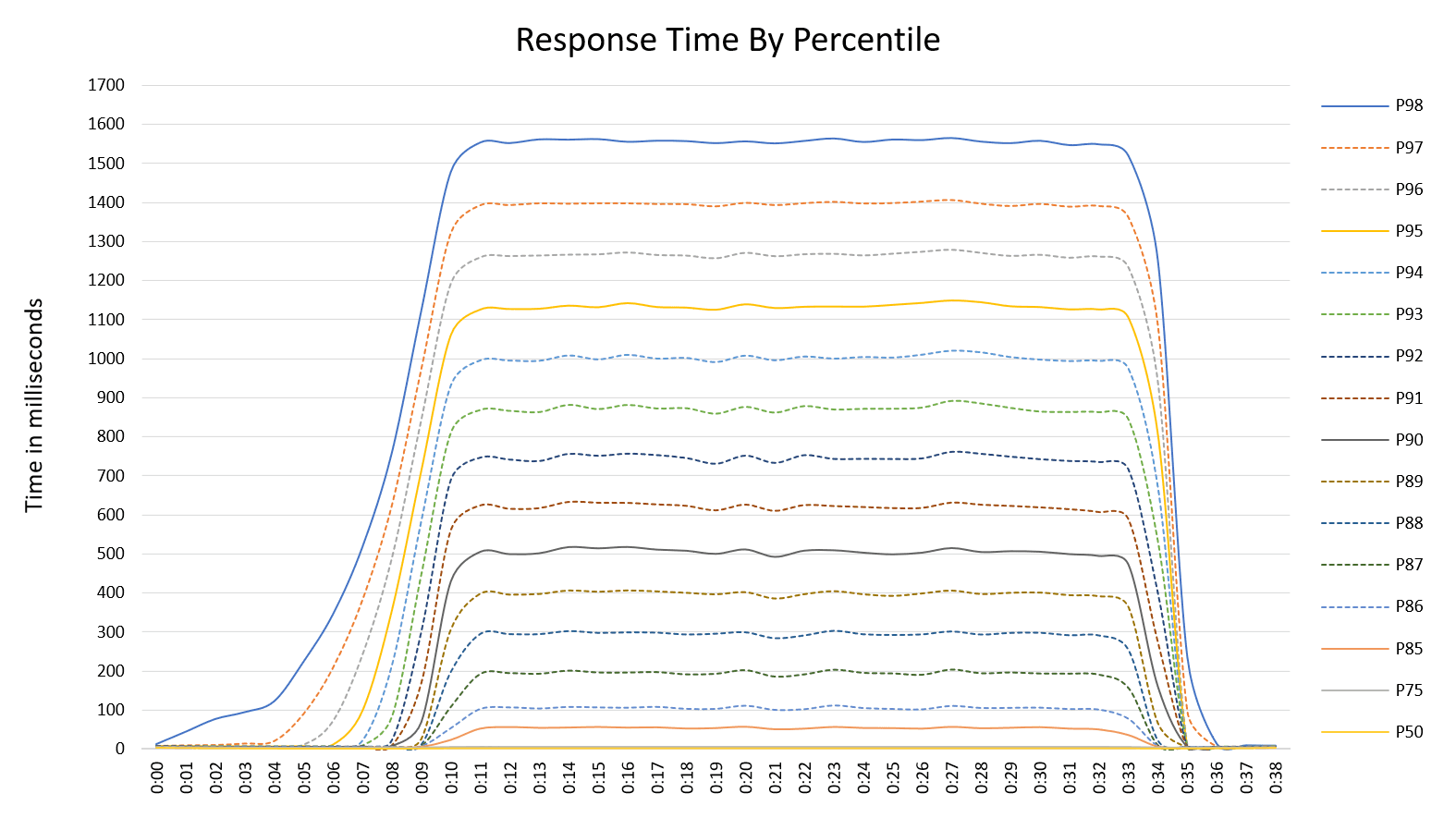
As seen above, the results achieved whilst serving one million requests per minute were:
- P50 averaged 3.7 milliseconds,
- P75 averaged 5.4 milliseconds,
- P85 averaged 54 milliseconds,
- P90 averaged 511 milliseconds,
- P95 averaged 1131 milliseconds,
- P98 averaged 1560 milliseconds,
Again, it is worth calling out the excellent consistency of the performance results within the percentile bands over time. The service produced stable and consistent results despite the transactional throughput exceeding 1 million requests per minute for the duration of the test once the ramp-up was complete.
Infrastructure Performance Analysis
When considering the performance metrics related to the compute infrastructure running the API, you can see that whilst we were running 120 Fargate tasks during the test, we probably could have reduced that number quite a bit, with the CPU utilisation barely reaching 45%.
That said, we strongly advise clients not to exceed a target of 50-60% when configuring autoscaling to utilise target tracking on the CPU dimension. This limitation ensures sufficient compute headroom is available to deal with spiking transactional load whilst scaling out is in progress. The only scenario where a higher CPU target would be suggested is when a well-defined secondary autoscaling target on Request Count per Target dimension has been set.
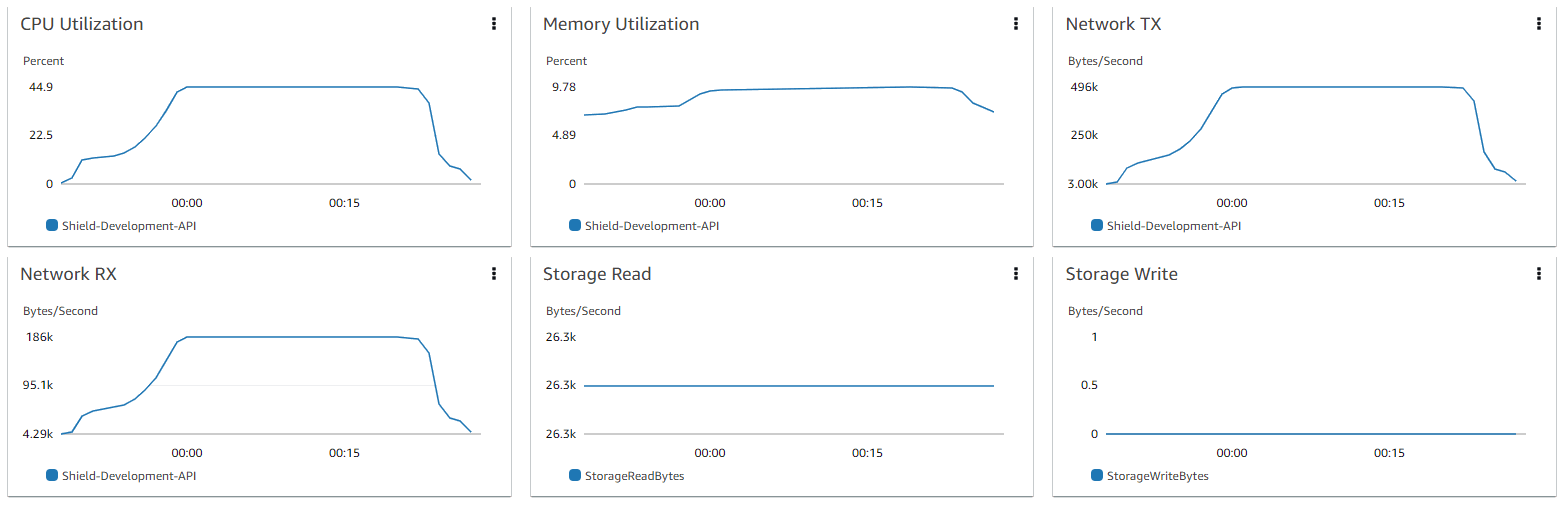
Database Cluster Performance Analysis
Looking at the comparative performance metrics from the database cluster (below), you can clearly see how the load was distributed across the read nodes within the cluster (column 3 being the primary node). Despite each node processing in excess of 2000 queries per second, the database CPUs were only averaging 5-10% of capacity. Additionally, IOPS was only peaking at 15-20% of available capacity.
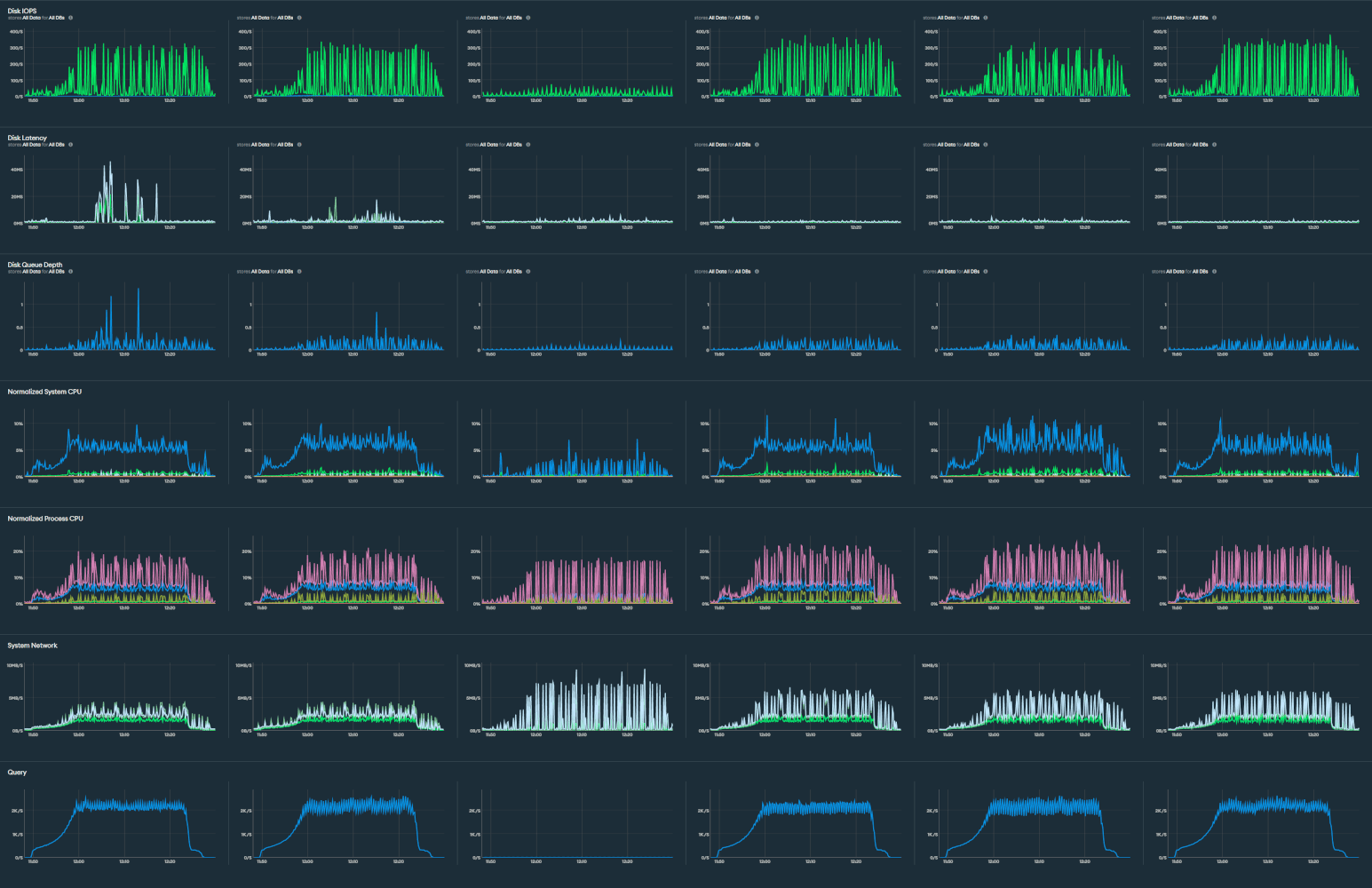
Looking at these results, one might be tempted to say that the database cluster was over-provisioned, but that is not the case. We are comfortable that the database was right-sized, and whilst it was clearly running efficiently and producing good results within the test parameters, our analysis showed that it was operating within ideal parameters for this configuration.
Cost Analysis
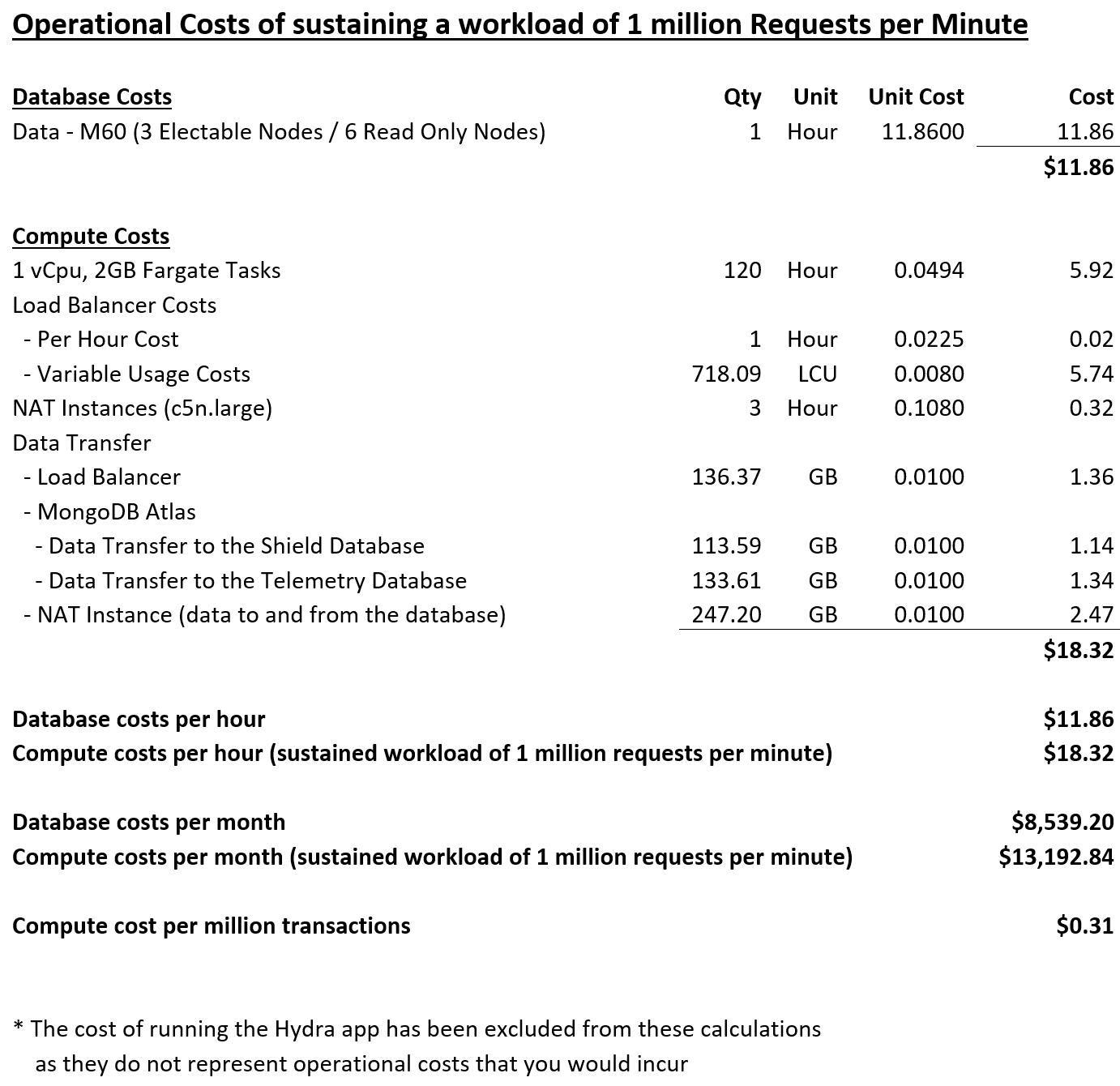
Below is the cost analysis of the infrastructure that serviced the test (normalised per hour). We managed to come in under budget on both of the test's cost dimensions. The database cost came in at 15% below budget, but most impressively, the service's variable operating costs (compute) came in at 69% below the target cost per million transactions.
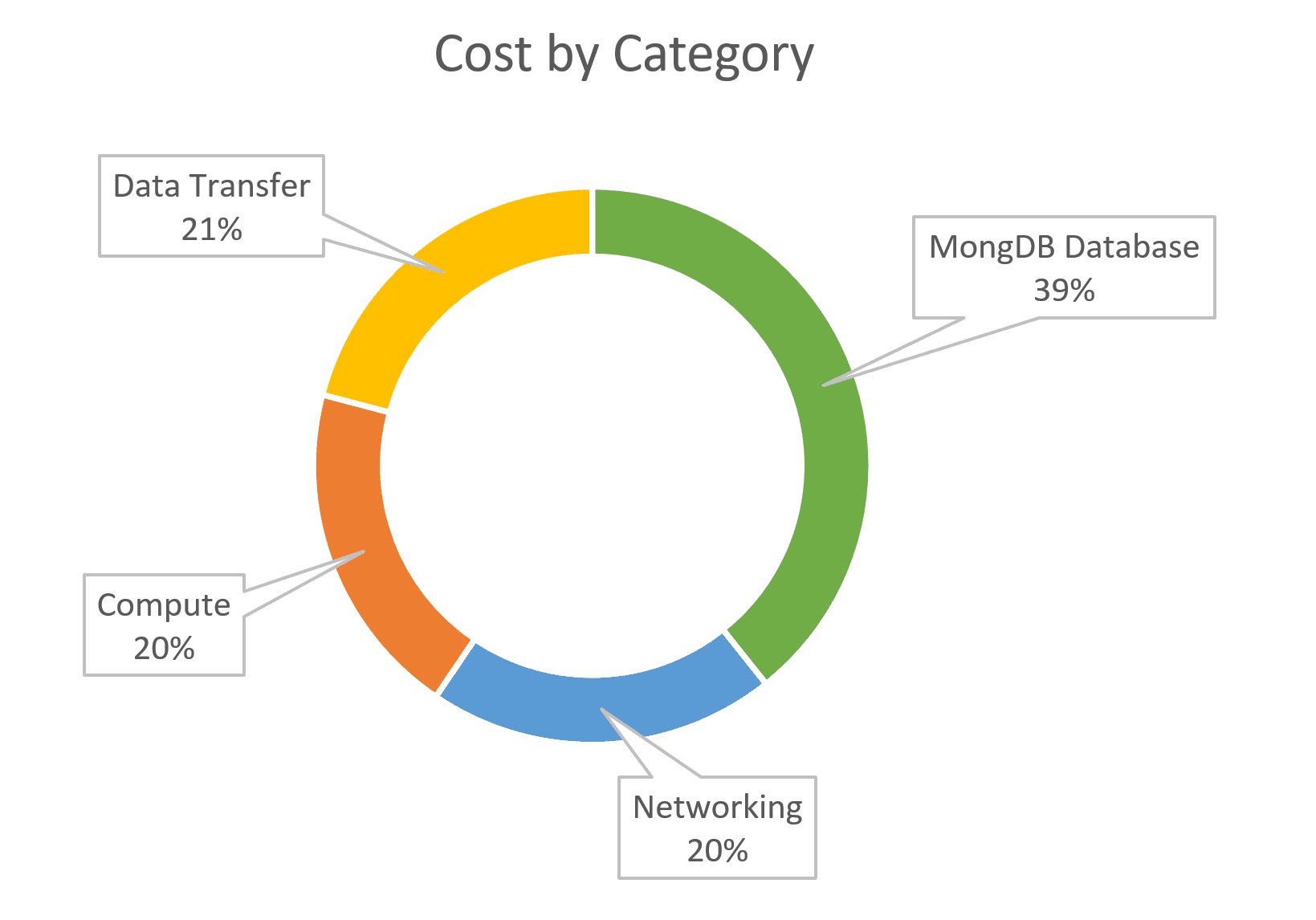
When considering the distribution of costs by category, we see a relatively even distribution, which indicates efficient relative sizing of the infrastructure components within the solution. This useful visualisation can often highlight that a database is being over-provisioned to compensate for an inefficient solution.
Summary
We trust that this report has been informative and beneficial to you. Our goal was to show that producing highly scalable APIs within a moderate operational budget is not only possible but easily possible. The hardware utilised in delivering this solution is what we consider well suited for a mid-range production workload; however, the implementation leaves considerable headroom to scale the solution up or down to meet a client's specific objectives and design parameters.
Appropriate sizing of the infrastructural components remains an essential part of the design process. Still, knowing that the software scales well and that many options are available to clients regarding how they deliver solutions is undoubtedly valuable.