Building an API serving a million requests per minute in 2 hours


Towards the end of last year, we collaborated with a client to understand the performance capabilities of a standard implementation of the Cloudize API Framework serving data from a MongoDB database.
Now, we all know that, in general, almost any problem within the tech space can be solved if you throw enough money at it.
That doesn't, however, represent the real world, where cost performance and value for money are critical factors in assessing a solution's viability. For that reason, we agreed to implement some budgetary constraints to the test. In doing so, we would not only be able to validate the solution's performance capabilities but its cost performance as well.
There are essentially two core operational cost categories to a solution such as this. The database and the compute environment.
For the database, we imposed a cost limitation of $10K per month, and for the entire compute environment, we set an overall budget limit of $1/million requests.
The next challenge was to define the details of the problem to be solved. We were specifically interested in measuring the read performance characteristics of the Cloudize API Framework, but we didn't want to sacrifice any of the standard bells and whistles that it offers out of the box (things like Authentication & Authorization, Object Level Access Management, Auditing, Telemetry, Error Logging & Service Accounting to name a few).

We created some data (100 million addresses, to be precise) and designed an API to securely serve the data to the consumer.
That's always the fun part. Cloudize has some internal tooling (which we call Tesseract), which allows us to visually design an API in next to no time. The cool thing about Tesseract is that it constantly produces a functional API as we iterate through the design. This makes the process extremely fast and, quite frankly, compelling. There is nothing like success to drive success.
Within two hours, the API was working as intended and deployed within AWS. For this project, we decided to deploy on Fargate, so we wouldn't have to worry about managing servers. AWS would automagically handle that for us.
const FIRST_ADDRESS_SEQ = 1;
const LAST_ADDRESS_SEQ = 100 * 1000000;
export default class AddressGetTask extends BaseTask implements IHydraWorkerTask {
async Execute(): Promise<boolean> {
const sdkConfig = new SDKConfiguration();
SetSDKConfigHostName(sdkConfig);
RegisterResourceClasses(sdkConfig);
try {
const addresses = new Addresses({ sdkConfig });
let seq = Math.floor(Math.random() * LAST_ADDRESS_SEQ) + 1;
if (seq < FIRST_ADDRESS_SEQ) seq = FIRST_ADDRESS_SEQ;
if (seq > LAST_ADDRESS_SEQ) seq = LAST_ADDRESS_SEQ;
addresses.Filter(AddressesFilter.Seq, ResourceFilterType.Equal, seq.toString(10));
await addresses.Find();
return true;
} catch (error) {
if (isError(error)) await this.logger.Write(LoggerMessageType.Error, error.message);
return false;
}
}
}The SDK (which Tesseract created for us) was published and pulled into a load-testing application. With a few more keystrokes, the app was simulating three thousand concurrent users accessing random resources from the API (using the code above).
The load-testing application was deployed into AWS (again, on Fargate), and the scene was set. It was time to scale the database up for the test.
Now, we exclusively use MongoDB Atlas for our database deployments. Outsourcing the management of your database infrastructure to the company that created the database is a total no-brainer. (If you're not convinced and still want to roll your own, call me, and I'll tell you about how, ten years ago, we lost our entire business overnight because we couldn't get a multi-terabyte self-managed database back online).
Anyway, I digress.
One of the great things about the database budget constraint we set for the test was that it was reasonable. We couldn't go berserk, but we still had a wide array of options available, and we could get creative in our solution architecture. We considered sharding, but in the end, given the read-heavy workload of the test, we decided that a single replica set, including some read-only secondary nodes, would do the job nicely (the Cloudize API Framework makes it really simple to automatically distribute read load evenly across your secondaries, of course, only if that's what you want to do).
The results were truly impressive. We ran some calibration tests, and from those, we determined how many load-testing applications we needed to have running simultaneously to produce the desired load. We scaled the client applications and watched as the API scaled up to meet the demand. Within a few minutes, the test was at full capacity, with over 17,500 requests per second being served by API (that's over 1 million requests per minute - not bad considering the budget constraints).
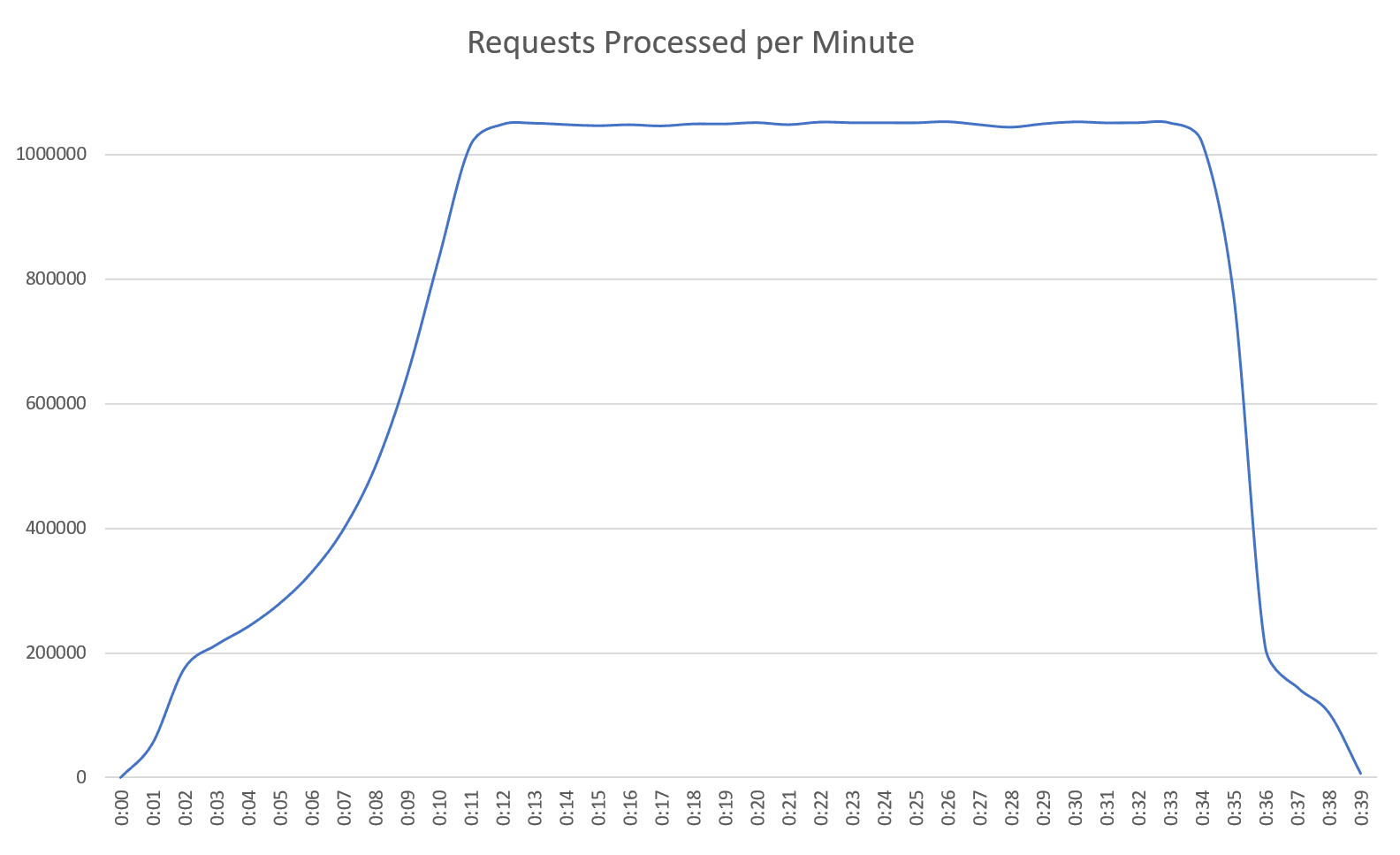
We had achieved our goal.
The database behind the solution cost $8,540 per month (although, in reality, we only ran it for a few hours), and the compute cost (including the load balancer, containers, networking and bandwidth) came in at $0.31 per million requests. [you could probably shave off another 25-30% if you run your containers on EC2]
Could we have pushed the solution even further? Absolutely - no doubt about it.
If you're interested in the nitty-gritty of the test, contact us, and we'll gladly send you the complete whitepaper.